
In Oracle, identity columns are a perfect way of generating a synthetic key value as the underlying sequence will automatically provide you with a unique value every time it’s invoked, pretty much forever.
One minor disadvantage of sequence generated key values is that you cannot predict what they will be ahead of time.
This may be a bit of an issue if you need to provide traceability between an aggregated record and it’s component records, or if you want to update an existing aggregation in a table without recalculating it from scratch.
In such circumstances you may find yourself needing to write the key value back to the component records after generating the aggregation.
Even leaving aside the additional coding effort required, the write-back process may be quite time consuming.
This being the case, you may wish to consider an alternative to the sequence generated key value and instead, use a hashing algorithm to generate a unique key before creating the aggregation.
That’s your skeptical face.
You’re clearly going to take some convincing that this isn’t a completely bonkers idea.
Well, if you can bear with me, I’ll explain.
Specifically, what I’ll look at is :
- using the STANDARD_HASH function to generate a unique key
- the chances of the same hash being generated for different values
- before you rush out to buy a lottery ticket ( part one) – null values
- before you rush out to buy a lottery ticket (part two) – date formats
- before you rush out to buy a lottery ticket (part three) – synching the hash function inputs with the aggregation’s group by
- a comparison between the Hashing methods that can be used with STANDARD_HASH
Just before we dive in, I should mention Dani Schnider’s comprehensive article on this topic, which you can find here.
Example Table
I have a table called DISCWORLD_BOOKS_STAGE – a staging table that currently contains :
select *
from discworld_books_stage;
TITLE PAGES SUB_SERIES YOUNG_ADULT_FLAG
---------------------- ---------- ---------------------- ----------------
The Wee Free Men 404 TIFFANY ACHING Y
Monstrous Regiment 464 OTHER
A Hat Full of Sky 298 TIFFANY ACHING Y
Going Postal 483 INDUSTRIAL REVOLUTION
Thud 464 THE WATCH
Wintersmith 388 TIFFANY ACHING Y
Making Money 468 INDUSTRIAL REVOLUTION
Unseen Academicals 533 WIZARDS
I Shall Wear Midnight 434 TIFFANY ACHING Y
Snuff 370 THE WATCH
Raising Steam 372 INDUSTRIAL REVOLUTION
The Shepherd's Crown 338 TIFFANY ACHING Y
I want to aggregate a count of the books and total number of pages by Sub-Series and whether the book is a Young Adult title and persist it in a new table, which I’ll be updating periodically as new data arrives.
Using the STANDARD_HASH function, I can generate a unique value for each distinct sub_series, young_adult_flag value combination by running :
select
standard_hash(sub_series||'#'||young_adult_flag||'#') as cid,
sub_series,
young_adult_flag,
sum(pages) as total_pages,
count(title) as number_of_books
from discworld_books_stage
group by sub_series, young_adult_flag
order by 1
/
CID SUB_SERIES YA TOTAL_PAGES NO_BOOKS
---------------------------------------- ------------------------- -- ----------- ----------
08B0E5ECC3FD0CDE6732A9DBDE6FF2081B25DBE2 WIZARDS 533 1
8C5A3FA1D2C0D9ED7623C9F8CD5F347734F7F39E INDUSTRIAL REVOLUTION 1323 3
A7EFADC5EB4F1C56CB6128988F4F25D93FF03C4D OTHER 464 1
C66E780A8783464E89D674733EC16EB30A85F5C2 THE WATCH 834 2
CE0E74B86FEED1D00ADCAFF0DB6DFB8BB2B3BFC6 TIFFANY ACHING Y 1862 5
OK, so we’ve managed to get unique values across a whole seven rows. But, lets face it, generating a synthetic key value in this way does introduce the risk of a duplicate hash being generated for multiple unique records.
As for how much of a risk…
Odds on a collision
In hash terms, generating the same value for two different inputs is known as a collision.
The odds on this happening for each of the methods usable with STANDARD_HASH are :
| Method | Collision Odds |
| MD5 | 2^64 |
| SHA1 | 2^80 |
| SHA256 | 2^128 |
| SHA384 | 2^192 |
| SHA512 | 2^256 |
By default, STANDARD_HASH uses SHA1. The odds of a SHA1 collision are :
1 in 1,208,925,819,614,629,174,706,176
By comparison, winning the UK Lottery Main Draw is pretty much nailed on at odds of
1 in 45,057,474
So, if you do happen to come a cropper on that 12 octillion ( yes, that’s really a number)-to-one chance then your next move may well be to run out and by a lottery ticket.
Before you do, however, it’s worth checking to see that you haven’t fallen over one or more of the following…
Concatenated Null Values
Remember that the first argument we pass in to the STANDARD_HASH function is a concatenation of values.
If we have two nullable columns together we may get the same concatenated output where one of the values is null :
with nulltest as (
select 1 as id, 'Y' as flag1, null as flag2 from dual union all
select 2, null, 'Y' from dual
)
select id, flag1, flag2,
flag1||flag2 as input_string,
standard_hash(flag1||flag2) as hash_val
from nulltest
/
ID F F INPUT_STRING HASH_VAL
---------- - - ------------ ----------------------------------------
1 Y Y 23EB4D3F4155395A74E9D534F97FF4C1908F5AAC
2 Y Y 23EB4D3F4155395A74E9D534F97FF4C1908F5AAC
To resolve this, you can use the NVL function on each column in the concatenated input to the STANDARD_HASH function.
However, this is likely to involve a lot of typing if you have a large number of columns.
Instead, you may prefer to simply concatenate a single character after each column:
with nulltest as (
select 1 as id, 'Y' as flag1, null as flag2 from dual union all
select 2, null, 'Y' from dual
)
select id, flag1, flag2,
flag1||'#'||flag2||'#' as input_string,
standard_hash(flag1||'#'||flag2||'#') as hash_val
from nulltest
/
ID F F INPUT_STRING HASH_VAL
---------- - - ------------ ----------------------------------------
1 Y Y## 2AABF2E3177E9A5EFBD3F65FCFD8F61C3C355D67
2 Y #Y# F84852DE6DC29715832470A40B63AA4E35D332D1
Whilst concatenating a character into the input string does solve the null issue, it does mean we also need to consider…
Date Formats
If you just pass a date into STANDARD_HASH, it doesn’t care about the date format :
select
sys_context('userenv', 'nls_date_format') as session_format,
standard_hash(trunc(sysdate))
from dual;
SESSION_FORMAT STANDARD_HASH(TRUNC(SYSDATE))
-------------- ----------------------------------------
DD-MON-YYYY 9A2EDB0D5A3D69D6D60D6A93E04535931743EC1A
alter session set nls_date_format = 'YYYY-MM-DD';
select
sys_context('userenv', 'nls_date_format') as session_format,
standard_hash(trunc(sysdate))
from dual;
SESSION_FORMAT STANDARD_HASH(TRUNC(SYSDATE))
-------------- ----------------------------------------
YYYY-MM-DD 9A2EDB0D5A3D69D6D60D6A93E04535931743EC1A
However, if the date is part of a concatenated value, the NLS_DATE_FORMAT will affect the output value as the date is implicitly converted to a string…
alter session set nls_date_format = 'DD-MON-YYYY';
Session altered.
select standard_hash(trunc(sysdate)||'XYZ') from dual;
STANDARD_HASH(TRUNC(SYSDATE)||'XYZ')
----------------------------------------
DF0A192333BDF860AAB338C66D9AADC98CC2BA67
alter session set nls_date_format = 'YYYY-MM-DD';
Session altered.
select standard_hash(trunc(sysdate)||'XYZ') from dual;
STANDARD_HASH(TRUNC(SYSDATE)||'XYZ')
----------------------------------------
FC2999F8249B89FE88D4C0394CC114A85DAFBBEF
Therefore, it’s probably a good idea to explicitly set the NLS_DATE_FORMAT in the session before generating the hash.
Use the same columns in the STANDARD_HASH as you do in the GROUP BY
I have another table called DISCWORLD_BOOKS :
select sub_series, main_character
from discworld_books
where sub_series = 'DEATH';
SUB_SERIES MAIN_CHARACTER
-------------------- ------------------------------
DEATH MORT
DEATH DEATH
DEATH DEATH
DEATH SUSAN STO HELIT
DEATH LU TZE
If I group by SUB_SERIES and MAIN_CHARACTER, I need to ensure that I include those columns as input into the STANDARD_HASH function.
Otherwise, I’ll get the same hash value for different groups.
For example, running this will give us the same hash for each aggregated row in the result set :
select
sub_series,
main_character,
count(*),
standard_hash(sub_series||'#') as cid
from discworld_books
where sub_series = 'DEATH'
group by sub_series, main_character,
standard_hash(sub_series||main_character)
order by 1
/
SUB_SERIES MAIN_CHARACTER COUNT(*) CID
-------------------- ------------------------------ ---------- ----------------------------------------
DEATH MORT 1 5539A1C5554935057E60CBD021FBFCD76CB2EB93
DEATH DEATH 2 5539A1C5554935057E60CBD021FBFCD76CB2EB93
DEATH LU TZE 1 5539A1C5554935057E60CBD021FBFCD76CB2EB93
DEATH SUSAN STO HELIT 1 5539A1C5554935057E60CBD021FBFCD76CB2EB93
What we’re actually looking for is :
select
sub_series,
main_character,
count(*),
standard_hash(sub_series||'#'||main_character||'#') as cid
from discworld_books
where sub_series = 'DEATH'
group by sub_series, main_character,
standard_hash(sub_series||main_character)
order by 1
/
SUB_SERIES MAIN_CHARACTER COUNT(*) CID
-------------------- ---------------------- -------- ----------------------------------------
DEATH MORT 1 01EF7E9D4032CFCD901BB2A5A3E2A3CD6A09CC18
DEATH DEATH 2 167A14D874EA960F6DB7C2989A3E9DE07FAF5872
DEATH LU TZE 1 5B933A07FEB85D6F210825F9FC53F291FB1FF1AA
DEATH SUSAN STO HELIT 1 0DA3C5B55F4C346DFD3EBC9935CB43A35933B0C7
The finished example
We’re going to populate this table :
create table discworld_subseries_aggregation
(
cid varchar2(128),
sub_series varchar2(50),
young_adult_flag varchar2(1),
number_of_books number,
total_pages number
)
/…with the current contents of the DISCWORLD_BOOKS_STAGE table from earlier. We’ll then cleardown the staging table, populate it with a new set of data and then merge it into this aggregation table.
alter session set nls_date_format = 'DD-MON-YYYY';
merge into discworld_subseries_aggregation agg
using
(
select
cast(standard_hash(sub_series||'#'||young_adult_flag||'#') as varchar2(128)) as cid,
sub_series,
young_adult_flag,
count(title) as number_of_books,
sum(pages) as total_pages
from discworld_books_stage
group by sub_series, young_adult_flag
) stg
on ( agg.cid = stg.cid)
when matched then update
set agg.number_of_books = agg.number_of_books + stg.number_of_books,
agg.total_pages = agg.total_pages + stg.total_pages
when not matched then insert ( cid, sub_series, young_adult_flag, number_of_books, total_pages)
values( stg.cid, stg.sub_series, stg.young_adult_flag, stg.number_of_books, stg.total_pages)
/
commit;
truncate table discworld_books_stage;
Once we’re run this, the conents of DISCWORLD_SUBSERIES_AGGREGATION is :

Next, we insert the rest of the Discworld books into the staging table :
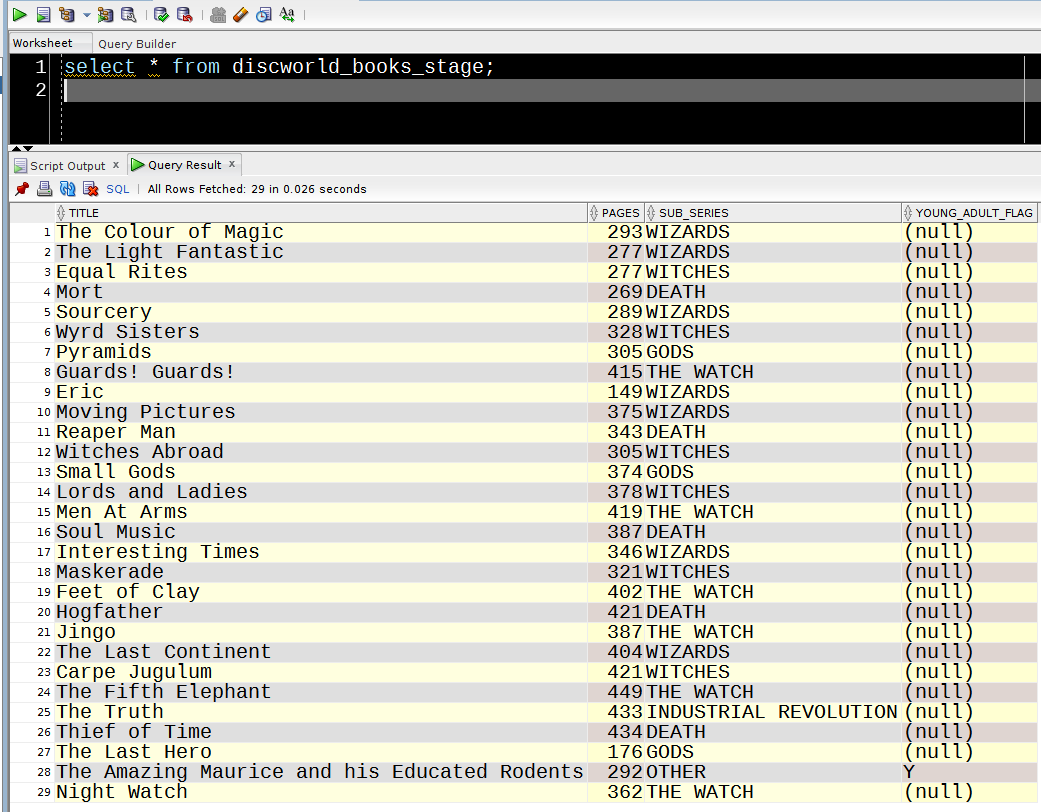
And run the merge again :
alter session set nls_date_format = 'DD-MON-YYYY';
merge into discworld_subseries_aggregation agg
using
(
select
cast(standard_hash(sub_series||'#'||young_adult_flag||'#') as varchar2(128)) as cid,
sub_series,
young_adult_flag,
count(title) as number_of_books,
sum(pages) as total_pages
from discworld_books_stage
group by sub_series, young_adult_flag
) stg
on ( agg.cid = stg.cid)
when matched then update
set agg.number_of_books = agg.number_of_books + stg.number_of_books,
agg.total_pages = agg.total_pages + stg.total_pages
when not matched then insert ( cid, sub_series, young_adult_flag, number_of_books, total_pages)
values( stg.cid, stg.sub_series, stg.young_adult_flag, stg.number_of_books, stg.total_pages)
/
7 rows merged.

Relative Performance of Hashing Methods
Whilst you may consider the default SHA1 method perfectly adequate for generating unique values, it may be of interest to examine the relative performance of the other available hashing algorithms.
For what it’s worth, my tests on an OCI Free Tier 19c instance using the following script were not that conclusive :
with hashes as
(
select rownum as id, standard_hash( rownum, 'MD5' ) as hash_val
from dual
connect by rownum <= 1000000
)
select hash_val, count(*)
from hashes
group by hash_val
having count(*) > 1
/
Running this twice for each method,replacing ‘MD5’ with each of the available algorithms in turn :
| Method | Best Runtime (secs) |
|---|---|
| MD5 | 0.939 |
| SHA1 | 1.263 |
| SHA256 | 2.223 |
| SHA384 | 2.225 |
| SHA512 | 2.280 |
I would imagine that, among other things, performance may be affected by the length of the input expression to the function.

